Une fois la source de données (S/4 HANA, SAP HANA, SAP BW, etc.) connectée, la première étape consiste à créer les tables dans le Data Builder, en masse ou individuellement, qui pourront ensuite être utilisées dans les vues. SAP DWC offre la possibilité d’importer une table sous deux formats : les remote tables, et les data flows.
- Remote Table (table distante)
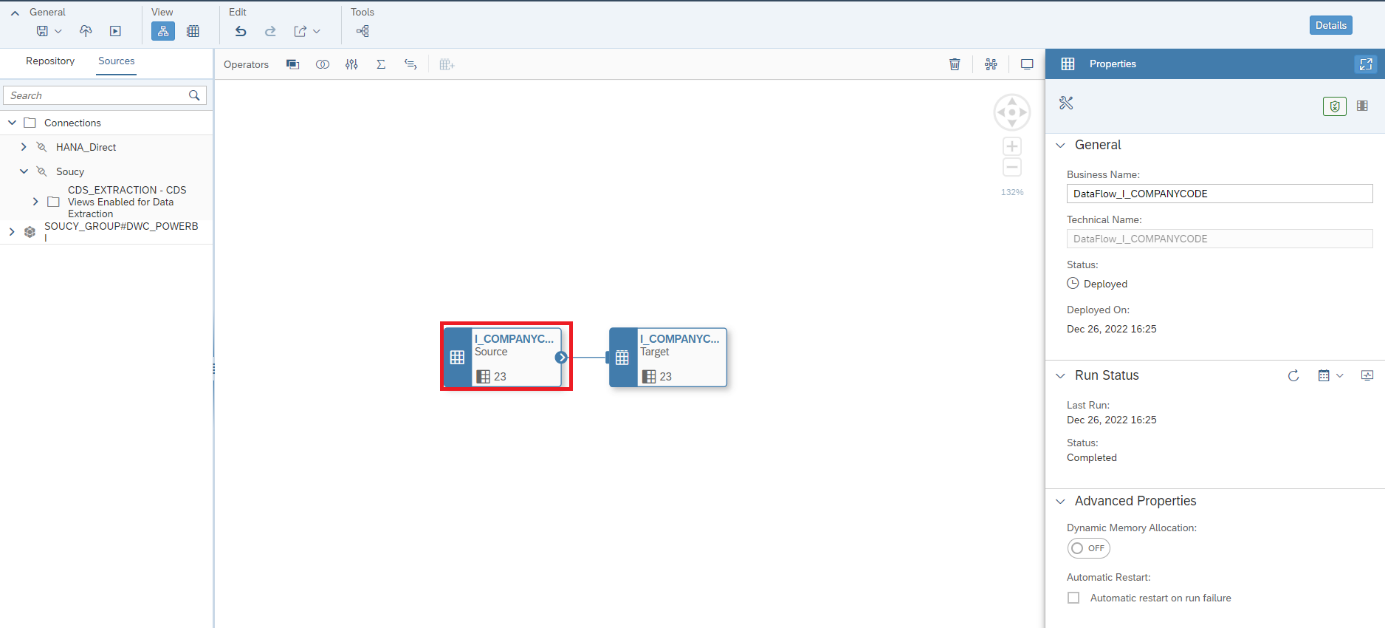
Les remote tables, ou tables distantes, sont des tables dont seules les métadonnées sont importées. Les données seront lues ultérieurement, lors de la consultation du report aval ou du data preview. Elles s’importent depuis l’écran d’accueil du Data Builder via cette commande ![]() qui permet d’accéder aux objets (tables et vues) des différents répertoires de la source et de les importer. En créant un espace dédié contenant un ensemble de tables, il est possible d’importer des tables en masse très rapidement. Leur utilisation nécessite comme prérequis l’installation d’un Data Provisioning Agent (DPA), pour les systèmes on-premise disponible sur help.sap.com.
qui permet d’accéder aux objets (tables et vues) des différents répertoires de la source et de les importer. En créant un espace dédié contenant un ensemble de tables, il est possible d’importer des tables en masse très rapidement. Leur utilisation nécessite comme prérequis l’installation d’un Data Provisioning Agent (DPA), pour les systèmes on-premise disponible sur help.sap.com.
- Data flow (flux de données)
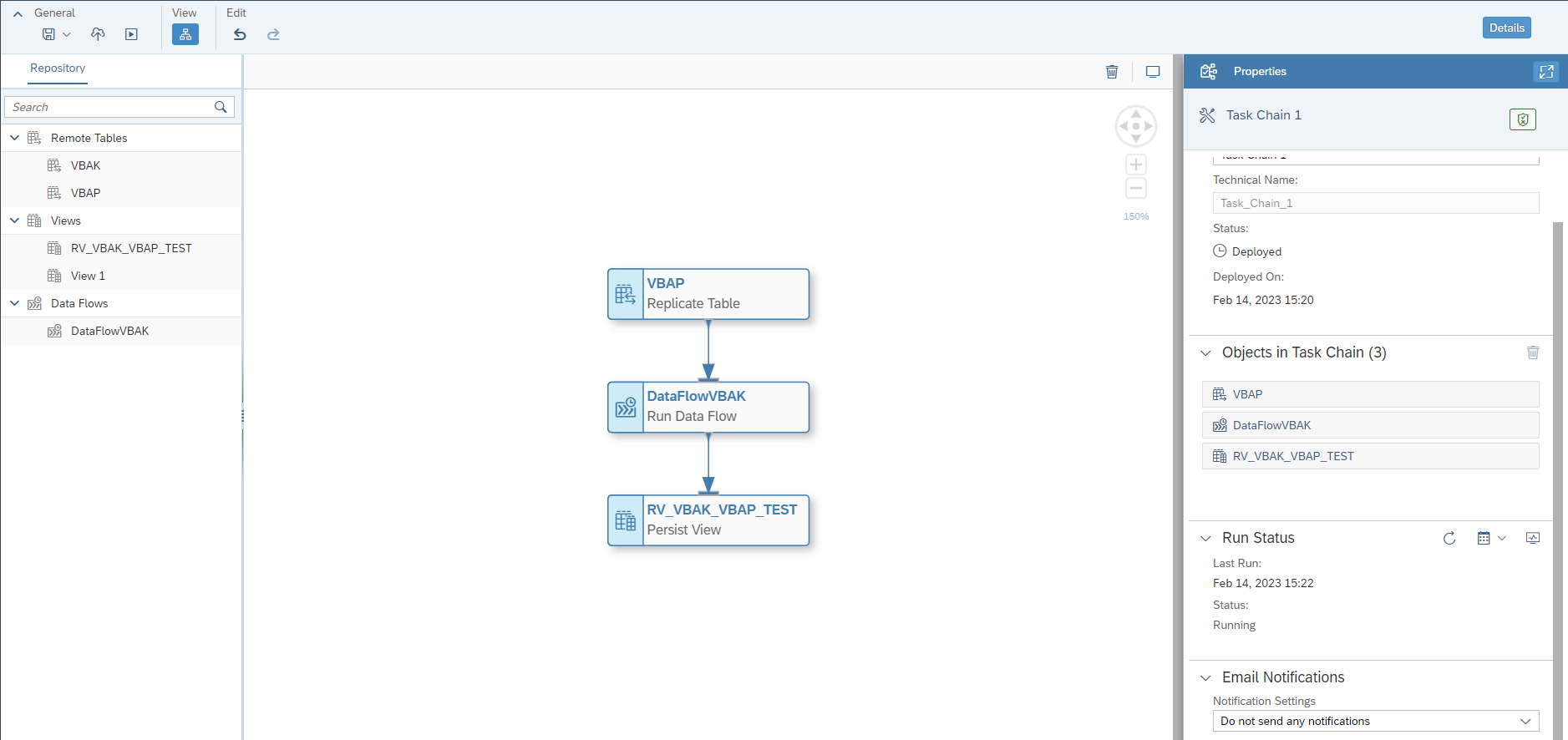
Les Data flows sont des tables répliquées depuis la source de données, contenant la définition mais aussi les données de la table d’origine. Pour qu’un Data Flow soit mis en place dans le Data Builder, il convient de préparer la connexion de la source de SAP DWC dans la section des caractéristiques :
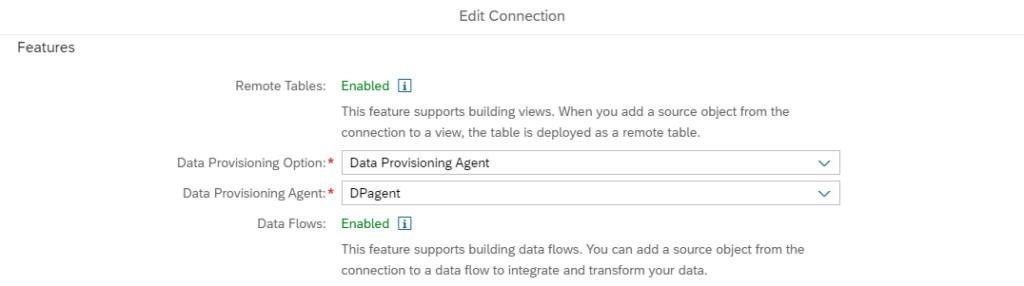


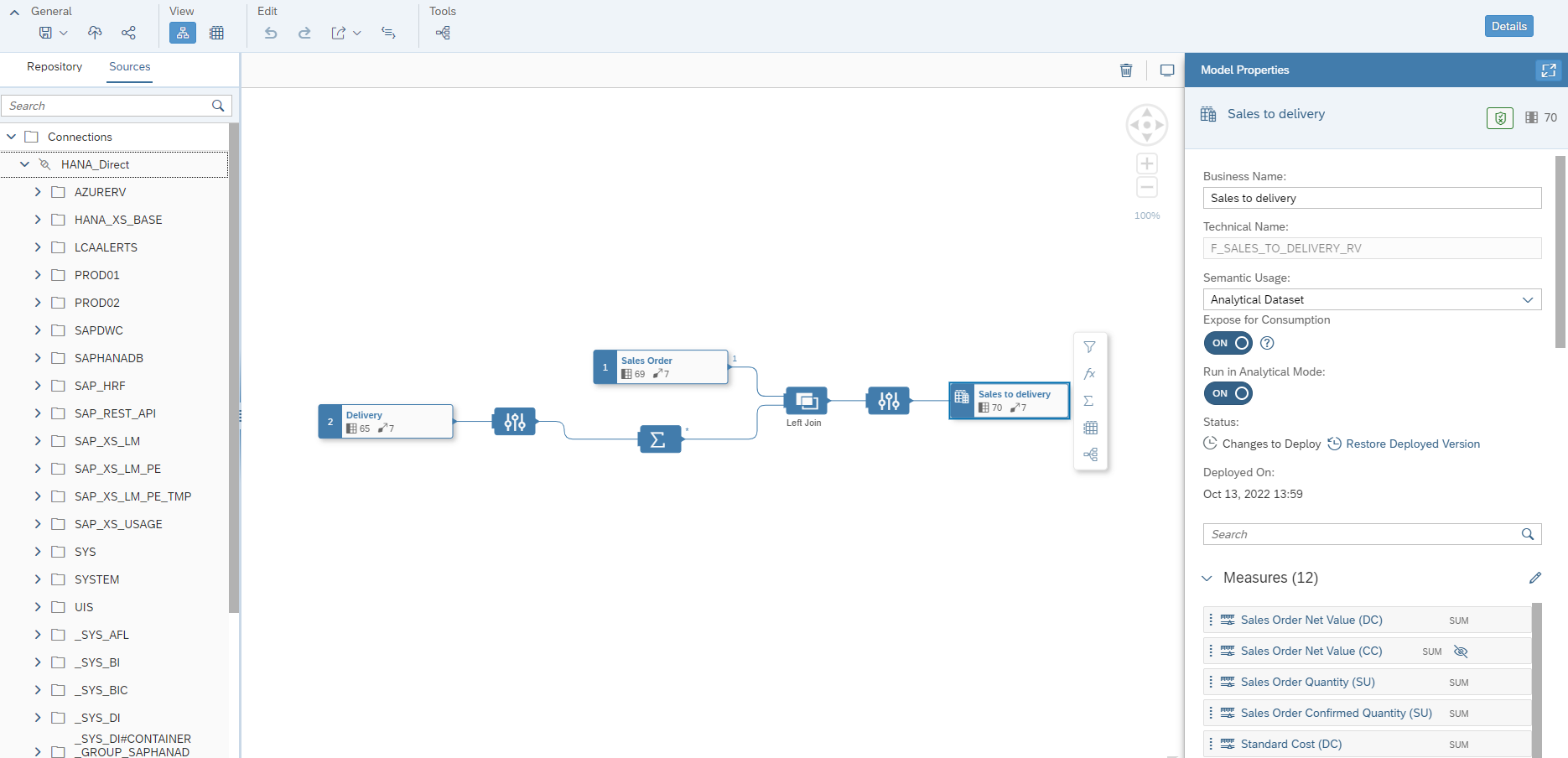
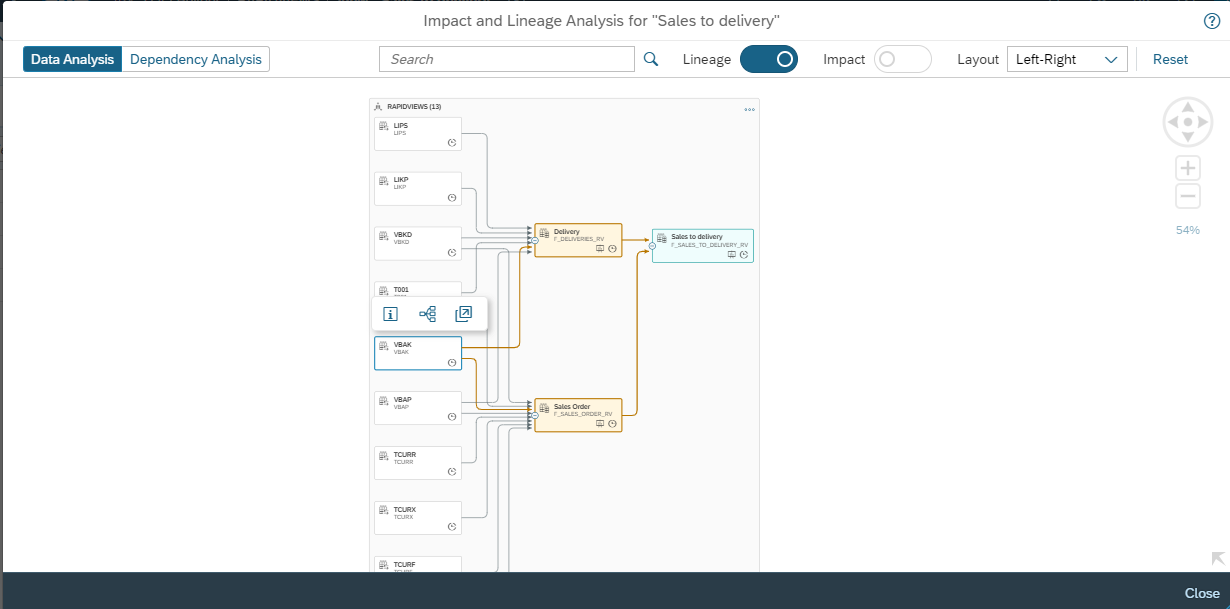
La vue graphique affichée ci-dessous a par exemple mobilisé les ressources suivantes lors de sa construction :
- Deux sources, drag-and-droppées depuis le volet de gauche : les vues de fait Delivery et Sales Order
- La vue Delivery est ensuite encapsulée dans une projection
 qui permet de transformer certaines données : masquer des champs, filtrer des données, ajouter des champs calculés. Il est possible d’en observer le résultat grâce à un data preview.
qui permet de transformer certaines données : masquer des champs, filtrer des données, ajouter des champs calculés. Il est possible d’en observer le résultat grâce à un data preview. - Cette projection est ensuite encapsulée dans une agrégation
 dans laquelle il est possible de sommer les mesures selon les attributs conservés dans l’agrégation.
dans laquelle il est possible de sommer les mesures selon les attributs conservés dans l’agrégation. - Les deux vues sont ensuite croisées au sein d’un left join
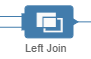 qui permet de sélectionner les champs clé à mapper.
qui permet de sélectionner les champs clé à mapper. - Ces données sont ensuite manipulables dans une projection ou une agrégation.
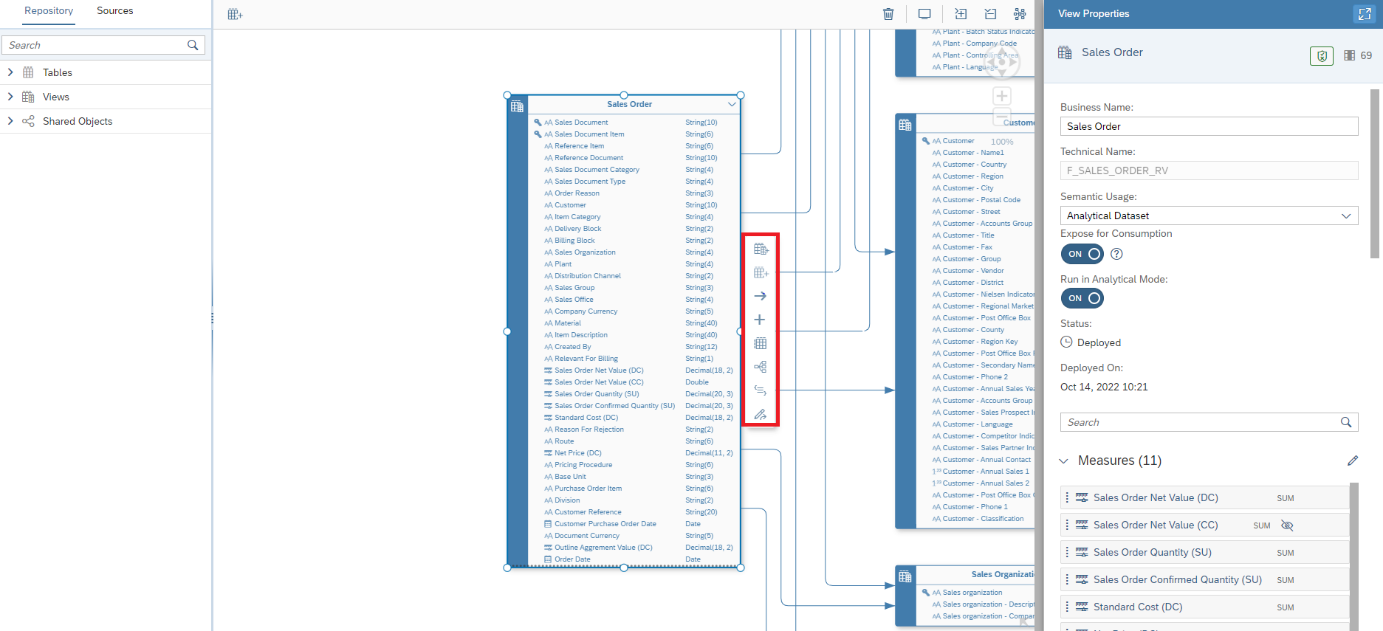
- Le dernier objet du modèle est la couche sémantique
 paramétrable : libellés, attributs ou mesures, champs masqués, associations, options de la vue… Les associations permettent de relier une vue de fait aux dimensions afin de créer un datamart.
paramétrable : libellés, attributs ou mesures, champs masqués, associations, options de la vue… Les associations permettent de relier une vue de fait aux dimensions afin de créer un datamart.