Stored online, the previous table would be stored as follows:
![]()
Once the data has been organised into columns, the attributes can be aggregated to further compress the data:
![]()
SAP offers a number of recommendations for building a high-performance view.
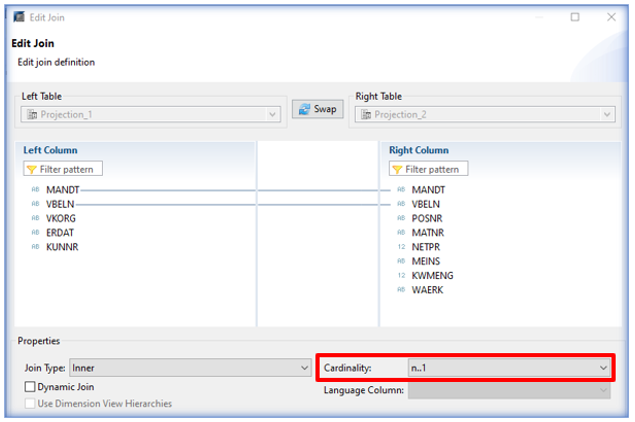
 Setting cardinalities for joins: although not mandatory, this parameter is required to speed up the search. The cardinality indicates the number of rows in a table which corresponds to the number of rows in the joined table. The match is made on one or more (n) rows. To identify the cardinality between two tables, the user can use the keys of each table, which indicate a unique record. In general, a left join between a fact table and a dimension table has a cardinality of N to 1.
Setting cardinalities for joins: although not mandatory, this parameter is required to speed up the search. The cardinality indicates the number of rows in a table which corresponds to the number of rows in the joined table. The match is made on one or more (n) rows. To identify the cardinality between two tables, the user can use the keys of each table, which indicate a unique record. In general, a left join between a fact table and a dimension table has a cardinality of N to 1.
Illustration: in a join between a customer order table (header data) and a customer description table (name, address, etc.), each customer reference corresponds to a single line of description. Conversely, each description can be assigned to several lines in the order table, since the same customer will place several orders.
The advantage of entering cardinality in terms of performance therefore lies in the fact that when the customer name (right-hand table) is assigned to the customer reference (left-hand table), the tool knows that it can stop browsing the other lines in the table. If the cardinality was not indicated, it would have scanned the entire table, uselessly, as no other results would have been found. This operation would have been performed for each record in the left-hand table.
The cardinality is set in the join editor:
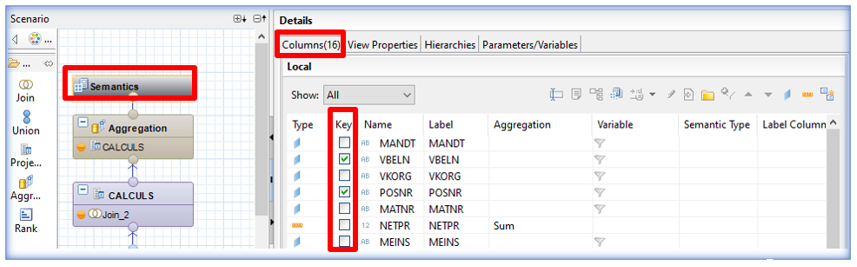
Key management: also a non-mandatory parameter, it is nevertheless essential to associate keys in the semantic layer of the analytical view in the interests of performance. SAP HANA automatically creates indexes on these key fields, which is relevant given that SAP HANA does not take into account the creation of indexes on analytical views. The key fields of a table or view are those that enable a single row to be identified.
To understand this concept, we can take the example of the sales order table again, but this time at item level. Each line will be unique as soon as the order reference/item reference pair is read: the key fields are then identified.
A view’s keys are set at the semantic level:
Correct management of record quantities: it is vital to correctly manage the number of rows in the construction of a view. Two views modelled differently, but with the same input and output data, may require very different quantities of resources depending on how they are constructed. The designer must bear in mind that each modelling operation must be carried out on the smallest possible number of lines. This implies a number of recommendations:
Place filters as close as possible to the tables being queried
Encapsulate the tables in a projection to filter the data immediately
Perform calculations on the smallest possible number of records: in general, in a projection close to the semantics, after filters and aggregations.
Table joins should be performed as a priority on key or indexed columns to speed up the search.
Reuse of existing views rather than creating a model for each requirement. Thanks to the persistence of analytical views on SAP HANA, calculations do not need to be performed again. It is also with this in mind that SAP HANA makes available the Star Join object, which consists of making dimension views (including attributes, which are views without measurements) gravitate around a factual view. In addition to the obvious time savings at the design stage, the performance gains are immense thanks to the persistence of the views.
It is therefore advisable to build dimension views to model frequently required attributes, even if there are only fields: for example, a VAT code and its description. The use of star joins is strongly recommended by the editor.